
Cree listas desplegables dependientes con validación de datos condicional
Esta publicación explora métodos sin macros para usar la función de validación de datos de Excel para crear un menú desplegable en la celda que muestra opciones según el valor seleccionado en un menú desplegable en la celda anterior.
Descripción general
Como ocurre con casi todo en Excel, existen varias formas de lograr el objetivo. Esta publicación explora tres de estas soluciones y, si tiene un enfoque preferido, publique un comentario. ¡Me encantaría conocerlo!
** NOTAS:
- A partir de Excel 2013 para Windows, podemos utilizar Slicers como una alternativa más sencilla a las soluciones que se presentan a continuación. Consulte la publicación de Slicers para obtener más información.
- Otra opción está disponible en versiones de Excel que incluyen funciones de matriz dinámica y rangos de derrame. Consulte esta publicación para obtener más información.
Las soluciones que exploraremos son:
- One Table: fórmulas más difíciles; gestión de datos continua más sencilla; No volátil; elimina opciones en blanco
- Dos tablas: fórmulas más sencillas; una gestión de datos continua más estricta; No volátil
- INDIRECTO – fórmulas más fáciles; volátil; incluye opciones en blanco
El enfoque de una tabla almacena todas las opciones desplegables (tanto para el menú desplegable primario como para el secundario) en una sola tabla, pero las fórmulas son las más difíciles de configurar inicialmente. Como resultado, una vez configuradas las fórmulas, es fácil agregar nuevas opciones desplegables primarias y secundarias sin actualizar las fórmulas. Este es el enfoque más “a prueba de balas” y una buena opción para usar cuando hay cambios frecuentes en las opciones desplegables o cuando desea asegurarse de que otros usuarios puedan agregar opciones fácilmente. Además, puede eliminar opciones en blanco del menú desplegable.
El enfoque de Dos Tablas almacena las opciones en dos tablas y sus fórmulas son un poco más fáciles de configurar inicialmente. Se debe tener especial cuidado al agregar nuevas opciones desplegables, lo que incluye agregar nuevas opciones principales a dos tablas y garantizar que la tabla secundaria esté ordenada en orden ascendente. Esta es una buena opción cuando hay cambios poco frecuentes en las opciones desplegables o cuando usted, el administrador del libro, actualizará las opciones y puede estar seguro de recurrir a la tabla secundaria.
El enfoque INDIRECTO utiliza la función INDIRECTA volátil. Las fórmulas de este enfoque son, con mucho, las más fáciles de implementar inicialmente; sin embargo, la función INDIRECTA es volátil, lo que significa que puede notar una disminución general del rendimiento en su libro de trabajo dependiendo de su tamaño, la cantidad de fórmulas, etc. Esta opción incluirá opciones en blanco en el menú desplegable. Esta es una buena opción cuando desea fórmulas simples y el libro de trabajo es relativamente pequeño. Tenga en cuenta que con este enfoque, si cambia el nombre de la tabla, también deberá actualizar las fórmulas de validación de datos relacionadas. ¡Gracias Danny por tu brillante sugerencia aquí!
Comenzaremos con mi enfoque preferido, el enfoque One Table. Es más difícil de configurar inicialmente, pero una vez hecho, las opciones son más fáciles de administrar con el tiempo. Después de analizar ese enfoque, analizaremos el enfoque de dos tablas. Tiene fórmulas más sencillas y, por lo tanto, es más fácil de configurar inicialmente, pero las opciones son más difíciles de gestionar con el tiempo. Concluiremos con la opción INDIRECTA, que tiene las fórmulas más sencillas.
Enfoque de UNA MESA
El enfoque incluye tres elementos de Excel que funcionan en armonía. La primera tarea es almacenar las opciones de validación de datos en una tabla. El segundo es configurar referencias con nombre que recuperen dinámicamente las opciones de validación de datos correctas de la tabla. El tercero es configurar las celdas de validación de datos según los nombres definidos.
Muy bien, basta de estrategia, entremos en la táctica.
Almacenamiento de opciones en una tabla
Lo primero es almacenar las opciones desplegables en una tabla. La función de tabla se introdujo por primera vez con Excel 2007, por lo que este enfoque sólo funciona con las versiones de Excel 2007 y posteriores.
La idea es almacenar las opciones para el primer menú desplegable como encabezados de tabla y las opciones para el segundo menú desplegable dependiente como datos de tabla.
Pongamos una ilustración para aportar algo concreto. Usemos regiones y repeticiones. Nuestra empresa tiene cuatro regiones y dentro de cada región varios representantes. Estamos configurando una hoja de trabajo que permite al usuario seleccionar una región y luego, dependiendo de la región seleccionada, un representante. Por lo tanto, necesitamos configurar un menú desplegable de validación de datos que permita al usuario seleccionar una región válida, y luego un segundo menú desplegable que le permita al usuario seleccionar un representante válido.
Podríamos almacenar todas las opciones de validación de datos, tanto para el menú desplegable de región como para el menú desplegable de representante, en la siguiente tabla, que se denomina tbl_choices para facilitar la referencia:
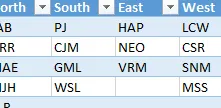
Los beneficios de almacenar las opciones en una tabla como esta son numerosos. En primer lugar, a los usuarios les resulta fácil modificar las opciones. Dado que las tablas se expanden automáticamente, cualquier opción nueva que se agregue se incluirá automáticamente en los menús desplegables, incluidas las nuevas regiones y representantes. El orden de clasificación de columnas y filas no importa, y la cantidad de opciones puede variar en cada columna. Una suposición es que no hay celdas en blanco entre repeticiones.
Ahora que las opciones están almacenadas en una tabla, pasemos a crear los nombres que se utilizarán en la validación de datos.
Referencias nombradas que recuperan las opciones correctas
Tenemos que configurar algunos nombres que podemos poner en el cuadro de diálogo de validación de datos. Por lo tanto, estos nombres deben devolver una referencia de rango válida. En lugar de configurar nombres únicos para cada una de las opciones, configuraremos un nombre para usar en el menú desplegable de región y un nombre para el menú desplegable de representantes. Una vez configurados los nombres, no será necesario actualizarlos y no necesitamos agregar nuevos nombres cuando un usuario agrega nuevas regiones.
El primer nombre es fácil, ya que simplemente se refiere a la fila de encabezados de la tabla. Podemos utilizar el sistema de referencia de tablas estructuradas incorporado para crear este nombre.
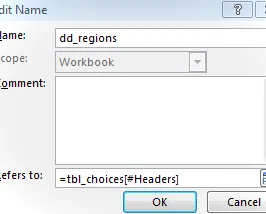
Usaremos el administrador de nombres (Fórmulas Administrador de nombres) para crear un nuevo nombre.
Nuestro nuevo nombre será dd_regions y hará referencia a la fila del encabezado de la tabla tbl_choices[#Headers] , como se ilustra en la siguiente captura de pantalla:
En un momento, usaremos este nombre personalizado en la validación de datos para la celda de región.
Ahora, creemos el nombre que necesitamos para el menú desplegable del representante. Para configurar el nombre, necesitaremos estar familiarizados con estas funciones de la hoja de trabajo:
- ÍNDICE
- FÓSFORO
Veamos qué necesitamos que logre la fórmula y luego veremos cómo ayudan estas funciones.
Versión fácil
Necesitamos una fórmula que recupere los valores de las columnas para la región seleccionada. Esto es bastante fácil si queremos devolver todas las filas, incluso las que están en blanco. Empezaremos con eso. Después de que esto funcione, mejoraremos la fórmula para que devuelva solo las filas con valores, de modo que la lista desplegable no tenga un montón de opciones en blanco en la parte inferior.
La idea es que necesitamos una fórmula que devuelva una referencia de columna basada en el encabezado de la tabla. Si te suscribes a este blog, esto te resultará familiar. Usamos una técnica similar para alimentar dinámicamente una función SUMIFS basada en el encabezado de la columna .
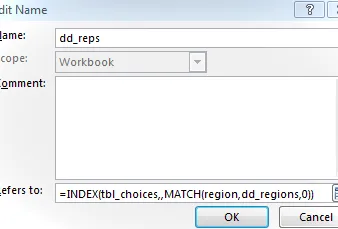
Básicamente, usamos la función ÍNDICE para devolver una referencia de columna y usamos la función COINCIDIR para determinar qué columna. Almacenaremos esta fórmula como una referencia con nombre para que sea fácil de usar con la validación de datos. Suponiendo que el valor de la región seleccionada está almacenado en la celda C5, a la que hemos llamado región por conveniencia, agregaremos una nueva referencia con nombre dd_reps que hace referencia a la siguiente fórmula:
=ÍNDICE(tbl_choices,,COINCIDIR(región,dd_regions,0))
La función ÍNDICE devuelve una referencia de rango que comienza con tbl_choices (argumento n.° 1), incluye todas las filas (argumento n.° 2) e incluye la columna cuyo encabezado coincide con la región seleccionada (argumento n.° 3, calculado por la función COINCIDIR).
A continuación se muestra una captura de pantalla como referencia.
Esta referencia con nombre devuelve todas las celdas de la columna de la región seleccionada, incluidas las celdas en blanco. Esta es la versión fácil y antes de pasar a la versión avanzada que excluye celdas en blanco, configuremos la validación de datos.
Configurar la validación de datos
Ahora que tenemos las dos fórmulas con nombre, simplemente podemos configurar la validación de datos en las celdas de entrada de región y representación.
La validación de datos para la celda de entrada de la región está configurada para permitir una lista igual a dd_regions , como se muestra a continuación:
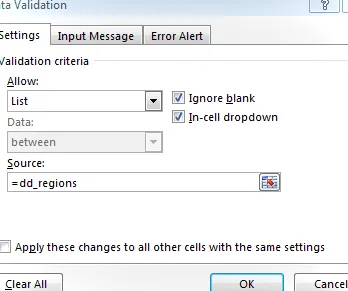
Cuando miramos la hoja de trabajo, vemos que ahora proporciona una lista de regiones, como se muestra a continuación:
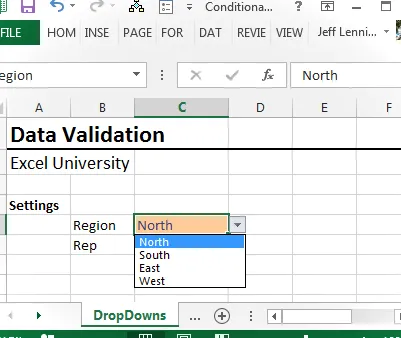
¡Hasta ahora, todo bien! Ahora, para el gran momento, en el menú desplegable de representantes condicionales, configuramos la validación de datos y permitimos una lista igual a dd_reps , como se muestra a continuación:
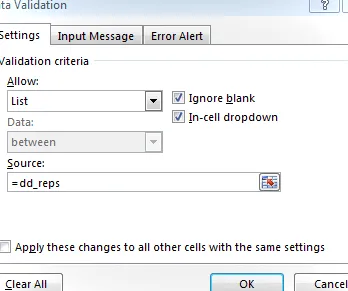
Si la celda de la región está en blanco, es posible que reciba un mensaje de alerta de error acerca de que el nombre se está evaluando como un error. Puede hacer clic de forma segura en el cuadro de diálogo de error.
Ahora, cuando volvemos a la hoja de trabajo, notamos que las opciones desplegables cambian dependiendo de la región seleccionada… ¡guau! ¡funcionó! Esto se ilustra en la siguiente captura de pantalla:
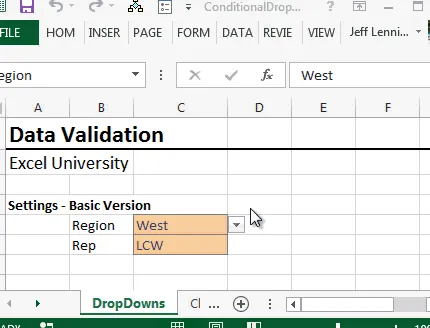
Y esa amigo mío, es la versión básica. Funciona bien, excepto que no me gusta cómo el menú desplegable incluye celdas en blanco. Sería mejor si de alguna manera pudiéramos decirle a Excel que solo incluya celdas con valores en la lista desplegable. Y podemos, pero se vuelve un poco complicado. Exploremos esta versión avanzada de la fórmula.
Versión avanzada
Si desea excluir filas en blanco del menú desplegable de representantes, necesitaremos mejorar nuestra fórmula con nombre.
Nuevamente, hay muchos enfoques para esta situación. Una posible solución es utilizar la función ÍNDICE para devolver un rango, de la siguiente manera.
Es fácil configurar una referencia de rango de estilo A1, simplemente especifica la esquina superior izquierda del rango y la esquina inferior derecha del rango, como A1:G12, o quizás B5:D10. La función ÍNDICE se puede utilizar de manera similar. Podríamos usar dos funciones ÍNDICE para especificar el rango, por ejemplo: ÍNDICE(…):ÍNDICE(…). La primera función ÍNDICE devuelve una referencia de celda que representa la celda superior izquierda del rango, y la segunda función ÍNDICE devuelve una referencia de celda que representa la celda inferior derecha del rango.
Para que la fórmula que usaremos con la validación de datos sea más fácil de entender, simplemente escribiremos un par de fórmulas auxiliares y las almacenaremos como nombres.
Primero, necesitaremos un atajo para hacer referencia al número de columna de la región seleccionada. Entonces, configuramos un nuevo nombre llamado dd_col_num que hace referencia a la siguiente fórmula:
=COINCIDIR(región,dd_regions,0)
Ahora, cada vez que necesitemos saber el número de columna de la región seleccionada, simplemente podemos referirnos a ella con el nombre dd_col_num .
A continuación, necesitamos un acceso directo para hacer referencia a la columna de la región seleccionada. No el número de columna, sino toda la columna de la tabla. Entonces, configuramos un nuevo nombre llamado dd_col que hace referencia a la siguiente fórmula:
=ÍNDICE(tbl_opciones,,dd_col_num)
Ahora, cada vez que necesitemos hacer referencia a la columna de la región seleccionada, simplemente podemos usar dd_col .
Finalmente, necesitamos un nuevo nombre para usar con el menú desplegable de representantes, por lo que configuramos dd_reps2 para que haga referencia a la siguiente fórmula:
= ÍNDICE (tbl_choices, 1, dd_col_num): ÍNDICE (tbl_choices, COUNTA (dd_col), dd_col_num)
Como puede ver, usamos la idea de ÍNDICE(…):ÍNDICE(…) para devolver el rango. La primera función ÍNDICE devuelve la celda superior izquierda y la segunda función ÍNDICE devuelve la celda inferior derecha. La primera función ÍNDICE busca dentro de tbl_choices (argumento n.° 1) y devuelve la referencia de celda en la intersección de la primera fila de datos de la tabla (argumento n.° 2) y la columna de la región seleccionada (argumento n.° 3, según lo calculado mediante la fórmula con nombre dd_col_num ) .
La segunda función ÍNDICE devuelve la celda dentro de tbl_choices (argumento n.° 1), en la intersección de la última celda con datos (argumento n.° 2, calculado por la función CONTARA) y la columna de la región seleccionada (argumento n.° 3).
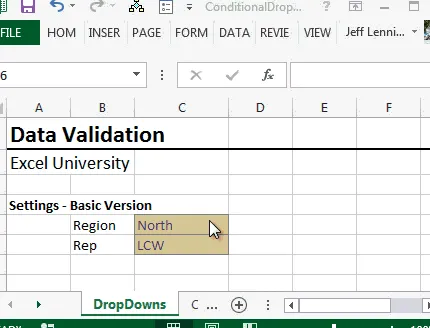
Una vez implementado esto, podemos usar la validación de datos para permitir una lista igual al nombre dd_reps2 . Esta vez, el menú desplegable excluye las celdas en blanco, lo que nos hace muy felices.
Esto se ilustra en la siguiente captura de pantalla:
Como alternativa al uso de la función CONTAR para contar el número de celdas con valores, podríamos usar la función COINCIDIR para encontrar la última celda con datos. Para demostrar este método, que incluiría celdas en blanco entre repeticiones, configuramos un nuevo nombre dd_reps3 de la siguiente manera:
=ÍNDICE(dd_col,1):ÍNDICE(dd_col,COINCIDENCIA("*",dd_col,-1))
Como puede ver, en lugar de intentar llegar a la última repetición con CONTAR, este enfoque utiliza COINCIDIR, haciendo coincidir un comodín (*), en la columna de repetición, y -1 para mayor que. Consulte la ayuda de Excel para la función COINCIDIR para obtener más detalles.
Las tres opciones, dd_reps , dd_reps2 y dd_reps3 , se incluyen en el archivo de descarga a continuación como referencia.
Enfoque de DOS TABLAS
El enfoque de dos tablas utiliza las mismas características y funciones subyacentes de Excel, incluida la validación de datos, rangos con nombre y tablas. Sin embargo, las fórmulas son más sencillas y, por tanto, este enfoque es más fácil de configurar inicialmente.
Un resumen de los pasos son:
- Configure una tabla para almacenar las opciones desplegables principales denominadas tbl_primary
- Configure un rango con nombre dd_primary que haga referencia a tbl_primary
- Configure la celda de entrada desplegable principal con validación de datos y permita una lista igual a dd_primary
- Configure una tabla para almacenar las opciones desplegables secundarias denominadas tbl_secundaria
- Configure un rango con nombre dd_secundario que recupere las opciones relacionadas
- Configure la celda de entrada desplegable secundaria con validación de datos y permita una lista igual a dd_secundaria
Aquí están los pasos detallados.
Primero, necesitamos almacenar las opciones desplegables principales en una tabla llamada tbl_primary:
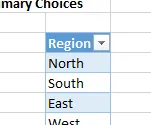
A continuación, configuramos un nuevo nombre personalizado dd_primary que hace referencia a la tabla:
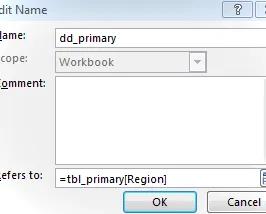
Luego, configuramos la validación de datos en la celda de entrada principal para permitir una lista igual a dd_primary:
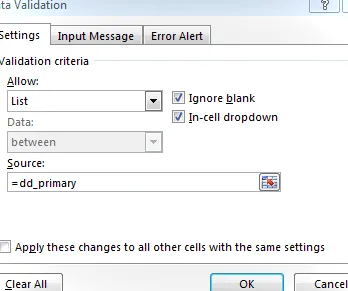
La celda de entrada principal resultante se muestra a continuación:
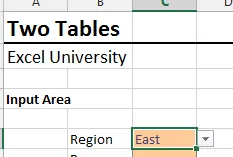
Ahora que el menú desplegable principal está funcionando, abordemos el menú desplegable secundario.
Configuramos la lista de opciones en una tabla llamada tbl_secundaria, que debe ordenarse en orden ascendente por la columna principal:
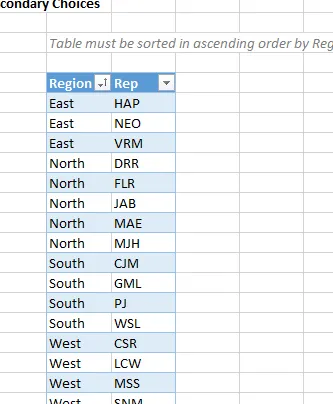
El siguiente es el rango con nombre dd_secundario. Ésta es la única parte complicada. Usaremos las funciones ÍNDICE/COINCIDIR para determinar las repeticiones relacionadas para la región seleccionada. Dado que nuestra celda de entrada principal está almacenada en una hoja de trabajo llamada Dos tablas en la celda C6, configuraremos el nombre dd_secundario para hacer referencia a:
=INDEX(tbl_secundario[Rep],MATCH('¡Dos tablas'!$C$6,tbl_secundario[Región],0),1):INDEX(tbl_secundario[Rep],MATCH('Dos tablas'!$C$6,tbl_secundario[Región],1),1)
Como puede ver, esta fórmula utiliza el operador de rango (:) para configurar el rango. La primera celda del rango está determinada por la primera función ÍNDICE. La última celda del rango está determinada por la última función ÍNDICE.
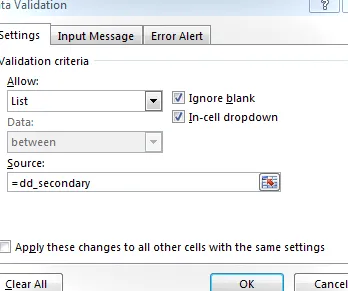
Luego, configuramos la validación de datos en la celda de entrada secundaria para permitir una lista igual a dd_secundaria:
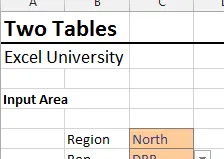
La hoja de trabajo resultante ahora contiene celdas de entrada desplegables condicionales:
Varias filas de entrada
Como puede ver, la captura de pantalla anterior supone solo una entrada, pero, ¿qué pasaría si necesitara configurar esto para que los usuarios puedan ingresar varias filas? No hay problema, el secreto está en el nombre dd_secundario.
Si bien los rangos con nombre a menudo se configuran con referencias absolutas, como el nombre dd_secundario usó la referencia absoluta ‘Two Tables’!$C$6, también se pueden configurar con referencias relativas. Cuando configura un nombre con una referencia relativa, la celda activa importa. Es decir, la celda activa en el momento de configurar el nombre indicará la ubicación base para la referencia relativa. Es fácil visualizar esta idea pensando en fórmulas normales. Cuando escribe una fórmula de celda normal que usa una referencia relativa, la referencia es relativa a la celda que contiene la fórmula. La misma idea se aplica al configurar una referencia con nombre. La celda activa, la que está seleccionada en el momento de abrir el cuadro de diálogo de nuevo nombre, se utilizará para determinar cómo se evalúa la referencia de celda relativa.
Podemos usar esta idea para configurar múltiples filas de entrada. Creamos el nombre dd_secundario usando una referencia relativa a la celda de entrada principal, mientras que la celda activa es la primera celda de entrada secundaria:
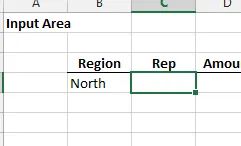
Dado que nuestro libro de trabajo ya tiene un nombre dd_secundario, usaremos dd_secundario2 en su lugar y estableceremos el nombre igual a:
=ÍNDICE(tbl_secundario[Rep],COINCIDIR(¡Múltiple!B7,tbl_secundario[Región],0),1):ÍNDICE(tbl_secundario[Rep],MATCH(¡Múltiple!B7,tbl_secundario[Región],1),1)
Notarás que en esta versión del nombre, la función COINCIDIR busca el valor en la hoja Múltiple en la celda B7, que es una referencia relativa. Dado que la celda activa cuando configuramos el nombre era C7, el nombre usará el valor de la izquierda.
Ahora, cuando configuramos la validación de datos para las celdas de entrada secundarias, permitimos una lista igual a dd_secundaria2.
Esto se demuestra en el archivo de muestra de la hoja de trabajo Múltiple.
Enfoque INDIRECTO
En este enfoque, configuramos una tabla para almacenar las opciones desplegables principales en la fila del encabezado y las opciones secundarias relacionadas en las columnas. A modo de ilustración, supongamos que la tabla se denomina tbl_reps .
En el cuadro de origen de la lista de Validación de datos para el menú desplegable principal, usaría esto:
=INDIRECTO("tbl_reps[#Encabezados")
Esto le indica a la validación de datos que convierta la cadena de texto “tbl_reps[#Headers]” en la referencia de tabla correspondiente a la fila del encabezado. Tenga en cuenta que, dado que el nombre de la tabla está incrustado en la fórmula, si cambia el nombre de la tabla, también deberá actualizar la fórmula de validación de datos.
Suponiendo que el menú desplegable principal está almacenado en A1, entonces usaría la siguiente fórmula en la fuente de la lista de validación de datos del menú desplegable secundario
=INDIRECTO("tbl_reps["$A$1"]")
La función INDIRECTA aquí le dice a Excel que convierta la cadena de texto en la referencia de tabla estructurada para el nombre de la columna identificada en A1.
La función INDIRECTA es volátil, lo que significa que se actualiza cada vez que se vuelve a calcular el libro. Esto puede afectar el rendimiento en libros de trabajo grandes. Sin embargo, en libros de trabajo pequeños no debería notar ningún impacto en el rendimiento y debería funcionar bien.
¡Gracias Danny por esta solución alternativa limpia!
Este enfoque se demuestra en el libro de trabajo ConditionalDropDown3b a continuación.
Conclusión
Los enfoques de una tabla y dos tablas son dos formas de proporcionar menús desplegables dinámicos utilizando la función de validación de datos de Excel. Si tiene un enfoque preferido o una forma de simplificar las fórmulas, publique un comentario a continuación.
Recursos adicionales
- Para descargar el archivo de Excel utilizado para las capturas de pantalla anteriores, que incluye la tabla, las fórmulas con nombre y las celdas de validación de datos: ConditionalDropdown
- Ejemplo de varias filas de entrada: ConditionalDropdown_2
- Usando el enfoque INDIRECTO: ConditionalDropdown3b
- Obtenga la lista desplegable secundaria de una tabla dinámica filtrada: ConditionalDropdownPT
- Si necesita ir a más de dos niveles, simplemente puede continuar con esta estrategia y crear tablas de opciones desplegables para cada menú desplegable dependiente adicional.
- Si no ha explorado las referencias con nombre, las tablas o la validación de datos, todos estos son temas cubiertos en el libro Volumen 1 de Excel University y en el curso de Excel en línea .
- Función INDIRECTA para extraer valores de tablas relacionadas
Deja una respuesta